
golang 비동기. 고루틴 스케줄러의 큐는 왜 그렇게 구성되었을까
해당 아티클은 다음 수준의 지식을 요구합니다.
- golang의 스케줄러에 대한 기본적인 이해
이전 아티클인 https://medium.com/@hyper201286/golang-비동기-goroutine은-왜-순서대로-실행되지-않을까-고루틴-스케줄링-1fedc5321775 에서 고루틴 스케줄러의 gmp 아키텍처와 기본적인 동작 방식을 알게 되었습니다. golang 스케줄러 내부에는 여러 p가 존재하고 스케줄러의 큐와 각각의 p가 큐를 가지고 고루틴이 이동하며 동작하는 방식으로 작동했습니다. 여기서는 좀 더 근본적인 의문에 다가가봅니다. 왜 큐가 이렇게 분리되어 있을까요? 또 그리고 이전 아티클에서 왜 큐를 하나로 실행했을 때, 0, 1, 2, 3, … , 99번의 고루틴을 넣었음에도 불구하고 0번이 아닌 99를 먼저 실행하도록 했을까요?
golang 스케줄러의 gmp 리뷰
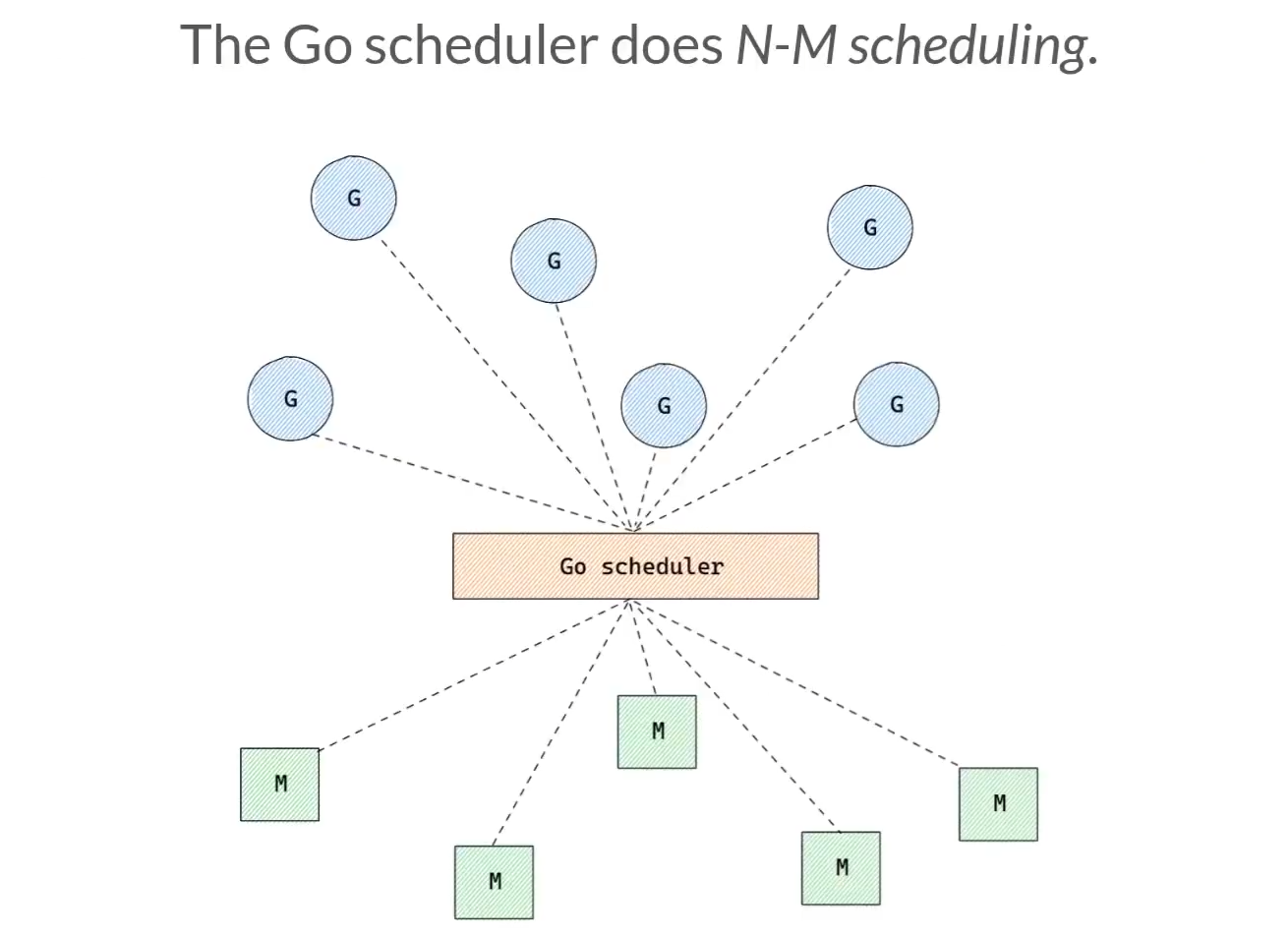
한편, 이전 아티클에서 언급하진 않았지만 golang에서 고루틴과 쓰레드의 대응은 N:M관계를 이루고 있습니다. 따라서 실행할 쓰레드의 개수를 제한해도 많은 수의 고루틴을 생성하여 애플리케이션을 동작시킬 수 있음을 볼 수 있었습니다.
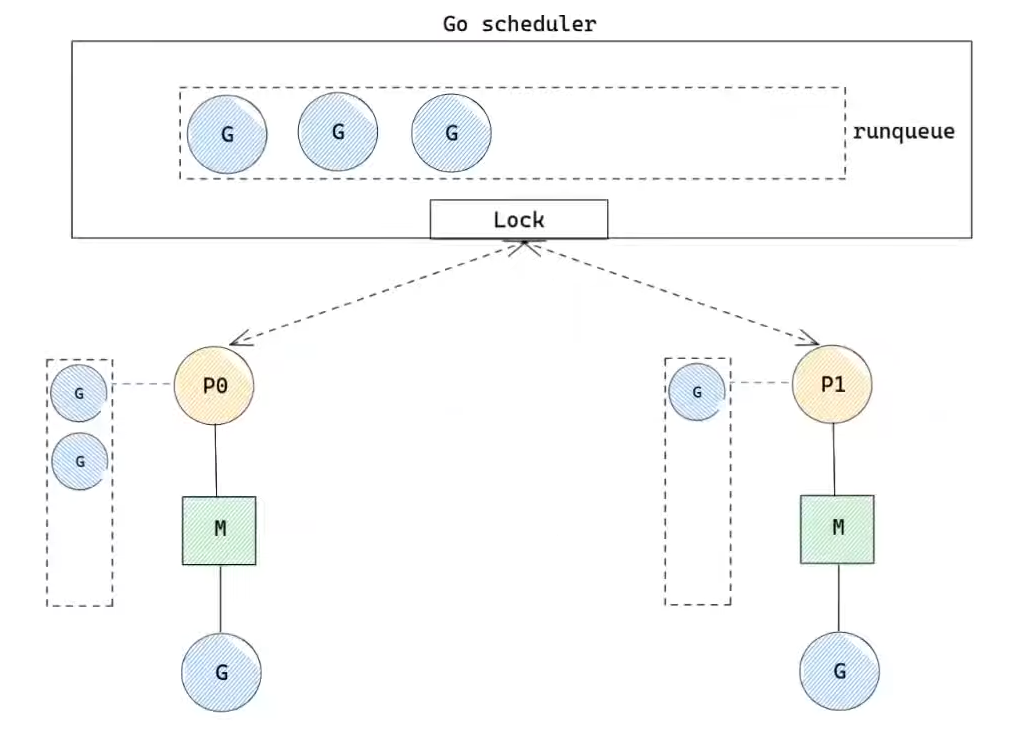
잠시 빠르게 golang 스케줄러의 gmp구조에서 고루틴 생성 및 실행 시 일어나는 과정에 대해 리뷰해봅시다.
- 고루틴 생성 시: p 내부의 lrq라 불리는 로컬 큐에 고루틴이 쌓이게 되고, 만약 로컬 큐의 용량보다 많아지면 grq라 불리는 전역 큐에 고루틴을 삽입하게 됩니다.
- 고루틴 실행 시: 61개 고루틴 실행마다 grq를 검사하여 가져오고, p의 내부 lrq, 없으면 grq, 없으면 작업 훔치기를 시도합니다. 실행은 최대 10ms를 기다리며, 이 이상으로 실행되는 경우 다시 큐에 적재합니다.
여기서 잠시 위의 스케줄러를 모르는 상태에서 고루틴과 쓰레드의 N:M스케줄링을 구현한다고 해봅시다. 이때 중요한 것은 N > M인 상황입니다. 만약 쓰레드보다 실행 준비 상태의 고루틴이 많은 경우, 실행을 하기 위해 대기할 어떤 장소가 필요하고 일반적으로 이런 자료구조로 큐를 사용하는 것은 잘 알려진 테크닉입니다.
이제부터는 가정을 해보면서 왜 고루틴 스케줄러는 이런 방식의 큐 구조를 갖게 되었는지 탐색해봅니다.
가정: 만약 lrq(local run queue)가 없는 경우
먼저 lrq가 없는 경우입니다.
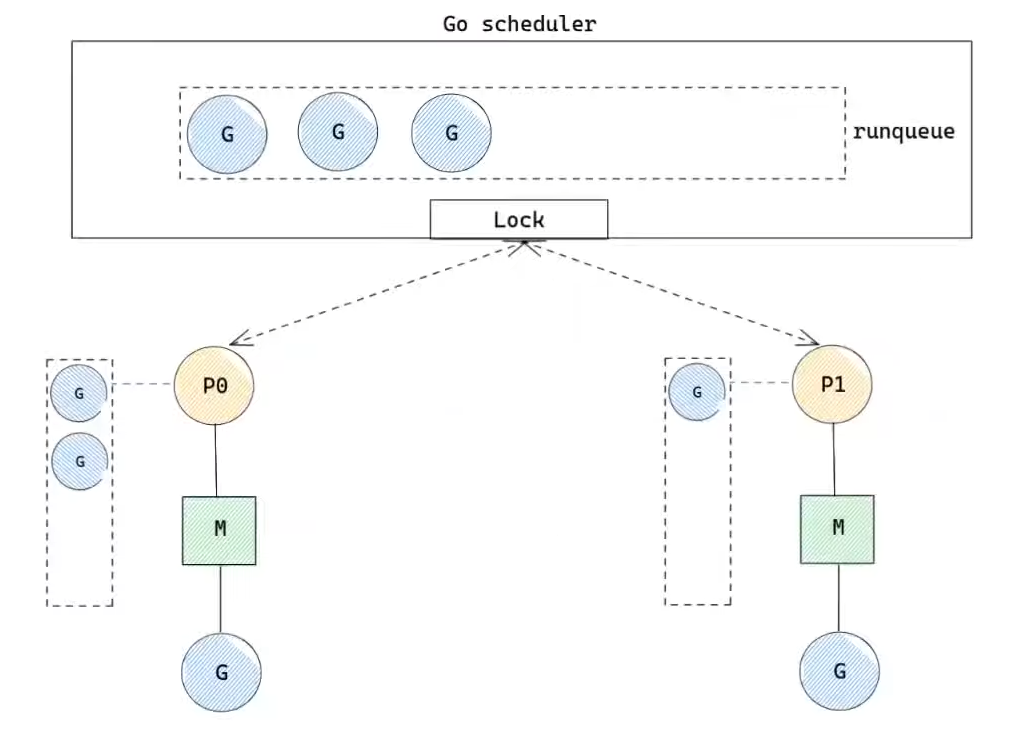
하나의 전역 큐에 실행해야 할 고루틴을 대기시킨 상태에서 여러 쓰레드가 고루틴을 가져오는 경우는 어떤 문제가 있을까요? 이 경우에는 쓰레드가 고루틴을 큐로부터 가져올 때마다 큐의 pop 연산에 동시성 문제를 회피하기 위해 락을 사용해야 합니다. 스레드가 동일한 큐에 접근하게 되어 경합이 발생할 수 있습니다. 이는 다수의 고루틴을 동시에 실행하려고 할 때 병목 현상을 유발할 수 있습니다.
따라서 golang 스케줄러는 p라는 자료구조를 만들어 쓰레드인 m별로 존재했던 고루틴들의 상태를 보관하고 로컬 큐를 활용하여 글로벌 큐에 접근하는 과정을 최소화했습니다. 이를 통하여 경합 문제를 줄여 성능을 높였습니다.
작업 훔치기와 스케줄러의 공정성
만약 p가 실행하는 어떤 고루틴이 p를 선점하는 시간이 늘어나면 어떻게 될까요? golang 스케줄러 내부는 큐 형태로 고루틴이 대기하고 있기 때문에 뒤에 존재하는 고루틴은 선점된 앞선 고루틴에 의하여 실행이 밀리게 될 것입니다. 이를 방지하려면 실행시간을 예측하여 짧은 테스크를 앞세워야 하는데 이것이 불가능할 수 있습니다. 따라서 golang 스케줄러는 일정시간(최대 10ms)이 지나면 다시 테스크를 대기시킵니다. 이런 방법으로 큐에 대기 중인 고루틴을 실행할 수 있도록 합니다. 이렇게 각 p마다 여러 개의 고루틴을 내부의 로컬 큐에서 관리할 수 있도록 하는 “지역성”이라는 특성을 부여했습니다.
그럼 고루틴은 어떻게 선택될까요? 로컬 큐에도 고루틴이 존재하고 글로벌 큐에도 고루틴이 존재합니다. 만약 어떤 p에서 실행 중인 고루틴이 중지되고 다른 고루틴을 선택해야 한다면, 다음을 따르게 됩니다:
- 먼저 탐색해야 하는 것은 로컬 큐입니다. 왜냐하면 바로 글로벌 큐를 조회하면 굳이 p를 분리할 이유가 없이 락을 획득해야 하기 때문입니다.
- 그러나 로컬 대기 큐만 사용하는 것은 문제가 있습니다. 예를 들어 로컬 대기 큐로부터 실행된 고루틴이 다시 고루틴을 생성하여 로컬 대기 큐로 고루틴이 삽입되어 특정 컨텍스트에서 무한히 대기가 될 수 있습니다. 이렇게 되면 전역 큐를 탐색할 수 없습니다.
- 따라서 일정 횟수가 지나는 순간(61번입니다), 강제로 전역 대기 큐를 확인하여 고루틴을 가져오게 됩니다.
- 이때 하나의 고루틴만 가져오지 않습니다. 한 번에 여러 개의 고루틴을 훔쳐 자신의 로컬 대기 큐에 집어넣습니다. 이렇게 최소한의 락만 걸도록 구현되어 있습니다.
- 만약 전역 대기 큐에 고루틴이 없는 경우, 다른 p의 큐를 확인하여 고루틴을 가져옵니다. 이때도 마찬가지로 하나가 아닌 여러 개의 고루틴을 가져오게 됩니다.
이렇게 전역 대기 큐와 로컬 대기 큐를 이용하여 부하 분산을 효율적으로 하고 경합을 최소화한 것을 이해했습니다. 그러나 여기서 또 문제가 발생합니다. 작업 훔치기를 하면 로컬 큐에 경합이 생겨 지역성을 해치지 않을까요? golang은 어떻게 이 문제를 해결했을까요?
FIFO와 LIFO의 조합
앞선 포스팅의 실험에서 p의 개수를 하나로 조정하고 0번부터 99번까지 고루틴을 생성하여 실행하는 코드를 동작시켰을 때의 순서는 99 → 0 → 1 → 2 → … → 97 → 98과 같았습니다. 즉, 마지막으로 생성된 고루틴이 제일 먼저 실행되고 그 뒤는 생성된 순으로 실행됩니다. 이를 그림으로 표현하면 아래처럼 크기가 1인 LIFO와, FIFO의 조합으로 이루어져 있다고 볼 수 있습니다.
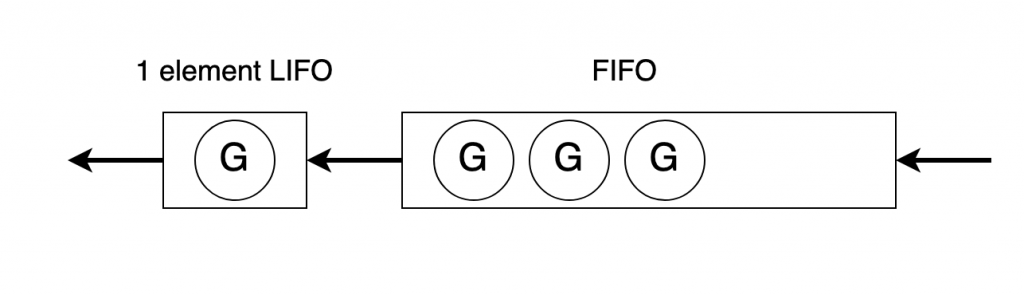
즉, 로컬 대기 큐 연산은 다음과 같습니다.
- put: 만약 LIFO가 찼다면 pop하여 해당 원소를 FIFO로 옮기고 LIFO에 집어넣습니다.
- pop: LIFO를 먼저 pop하고 없으면 FIFO를 pop합니다.
해당 구조로 스케줄러 큐를 설계하면 다음과 같은 이점을 얻을 수 있습니다.
- 작업 훔치기 시 FIFO만 탐색: 작업 훔치기는 runtime/stealWork함수에서 실행되고 해당 함수는 runtime/runqsteal을 호출합니다. 해당 코드는 p의 runnext를 탐색하지 않고 FIFO에서 고루틴을 가져오게 됩니다. 따라서 runnext, 즉 LIFO를 훼손하지 않고 실행과 별개로 FIFO에 존재하는 고루틴을 가져올 수 있습니다.
- 캐시 친화: 고루틴을 생성한 쓰레드에서 고루틴을 실행하기 쉬워지므로 캐시를 활용하기 용이해집니다. 그래서 최근 생성된 고루틴을 캐시 히트를 높여 빠르게 실행할 수 있게 됩니다.
그래서 큐는 왜 그렇게 동작할까?
자, 위에서 찾은 내용을 정리해봅시다.
Q1. 로컬 큐와 글로벌 큐로 분산된 이유?
A1. 글로벌 큐를 여러 쓰레드가 동시에 접근하여 고루틴을 가져갈 경우 경합이 많이 발생합니다. 따라서 글로벌 큐에 대한 접근을 줄이고 한 번 접근 시 여러 개의 고루틴을 가져가도록 구현되었습니다.
Q2: 만약 하나의 로컬 큐에서 테스크가 길어지는 경우 이때 어떻게 고루틴을 공정하게 실행하는지?
A2: 하나의 테스크에 최대 시간을 지정하고 초과 시 재대기합니다. 만약 다른 p의 로컬 대기 큐가 소진됐다면, 글로벌 큐에서 고루틴을 가져오거나 작업 훔치기를 통해 다른 p의 작업을 가져와 실행합니다.
Q3: 작업 훔치기가 일어나면 지역성을 해치게 되는데, 이를 방어하기 위한 전략?
A3: 작업 훔치기시 지역성이 떨어지는데, 이를 방지하기 위해 로컬 큐를 크기가 1인 LIFO와 FIFO로 구성합니다. 해당 구성으로 다음의 이점을 얻습니다.
- 당장 LIFO에서 실행할 고루틴을 무시하고 FIFO만 탐색합니다.
- LIFO에 최근에 생성한 고루틴이 존재하므로 캐시 히트를 높여 빠르게 실행할 수 있도록 합니다.
다음에는 golang의 동기화를 맞추는 패키지를 알아봅시다!

Leave a comment